DataXstream is bringing Artificial Intelligence and Machine Learning into the OMS+ solution. OMS+ is an SAP certified Order Management Solution compatible with SAP ECC and SAP S/4HANA.
AI in OMS+ Project Overview
Transcript:
Cailin: I’m Cailin, I am in marketing at DataXstream and today we have Juichia Holland with us. Juichia did an internal presentation earlier this fall that was really interesting about a project that she has been assigned to work on to meet some customer needs within OMS+. OMS+ is an Order Management / Point of Sale product offered by DataXstream. So we have decided to tease out and let people know what we are working on because it is really exciting, and to give Juichia the opportunity to give us an overview of the project and to share where it is now. And so Juichia if you would introduce yourself and explain your background and then we will go into the overview.
Juichia: Hi I am Juichia and I have been working in SAP for 15 years, I started doing integration with DataXstream and moved into PI and CE and did some software development and last year I transitioned into data science and artificial intelligence because I think it is a very exciting field. This is my first industry project. So I’m very excited.
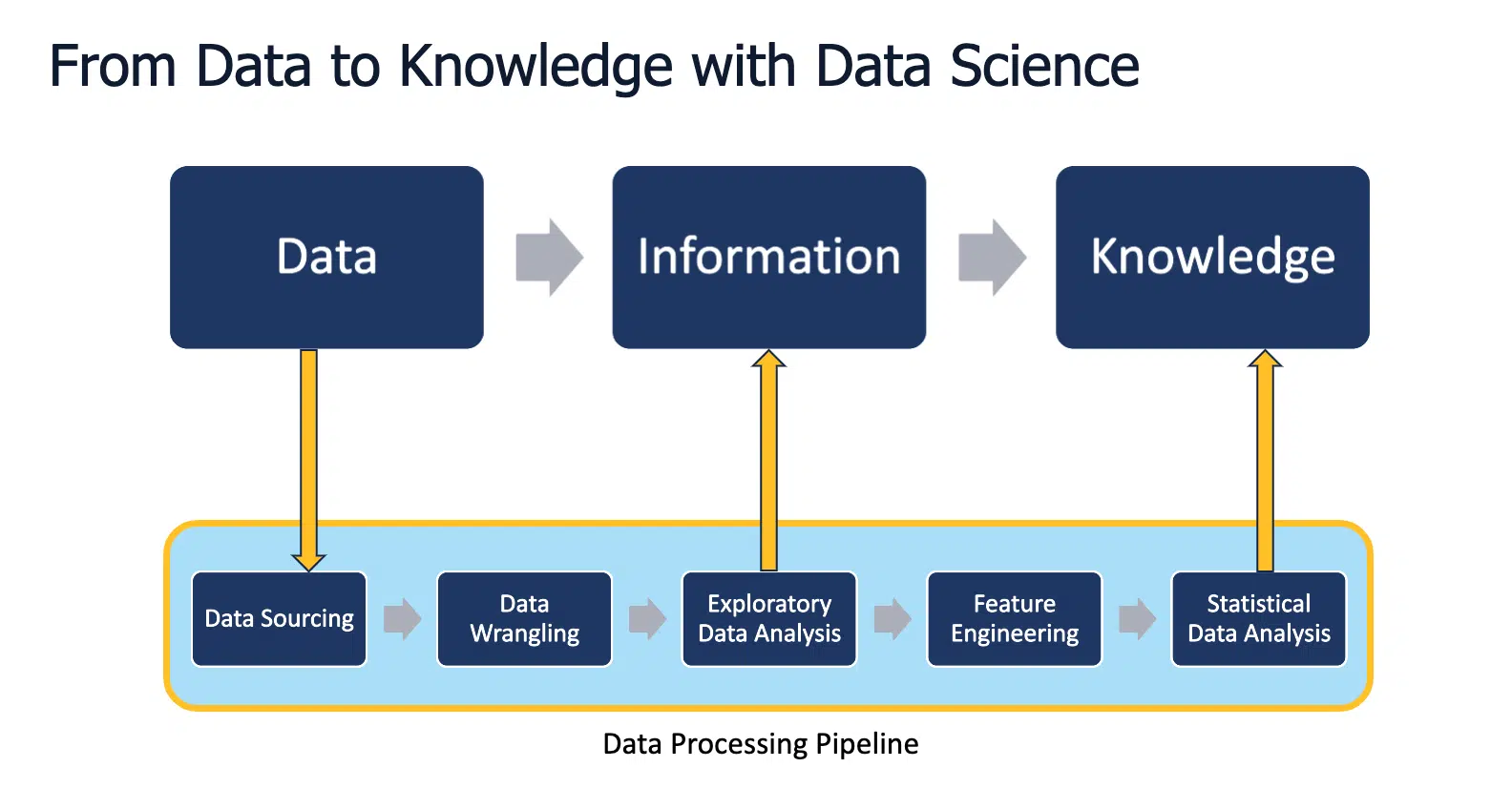
Cailin: It’s really exciting. So in the presentation you showed us a slide and I don’t know if I gave you screen share permission (Jeff inserted a video beep here while Cailin sorted out her user errors) So I just thought this was a helpful visual of what the overview was of what you are working to explain the overall project and process.
Juichia: So we are bringing machine learning and artificial intelligence into OMS+. And the first customer requirement we have is in regard to matching material descriptions from customer requests into SAP system. So in order to design a solution using machine learning for this requirement we are using data science to scope out the data that we have and the possibilities in machine learning that we have. Data science through a pipeline of steps with the data from the customer and the first thing that we do is to source the data from the customer usually from their database. And then we take that data and we wrangle with the data which means we remove the duplicates, we check if the data is valid, we format it and we kind of make everything ready for the machine to learn from. And then that transforms the data into information in the exploratory data analysis step where we do some initial statistical analysis of the data. We find out about the number of words in the material descriptions, the number of characters in the material descriptions, and other information like that. And then from such information we can formulate hypotheses about the data and about the problem that we have at hand. We then move into feature engineering, which is a step in data science where we generate additional features of the data that we have. For example, with material descriptions we might make another attribute about a description like number of words in that description or number of characters in that description or the similarity score between the descriptions. In feature engineering we make these additional features which we can then use in the final step of statistical data analysis where we use statistical methods to analyze and to confirm the hypotheses that we have come up with in the prior steps.
Cailin: There are a couple interesting things from the internal presentation that sort of stood out to me. One of them was that I have however many years of working vocabulary to say this is relevant to this but that is something you have to teach the system based on each customer’s database right? In one customer’s database there are certain relevancies or certain similarities that should show up in a search and that is going to be independent to each customer?
Juichia: Right. So when the customer sales representatives perform a search based on a customer requirement, for example their customer has asked for a pipe and that representative maybe because he has worked with that customer for a long time, he knows “oh this customer when they ask for a pipe they actually mean this this tube or this gauge in our system and that is the material that I need to pick from our SAP system.” Humans know immediately what is relevant based on experience, but the machine doesn’t know what is relevant, unless we give it that data. So to start with we have to be be able to convert the data to numerical features so that the machine can use the features to determine how similar a customer request is to an SAP material. To begin with the machine can only use the numerical scoring in comparison to understand the data but going forward what we hope to do is to be able to engage the sales representatives feedback whether the search results are relevant and we can give that to the system and the system can use that to learn more about the data and make more accurate predictions.
Cailin: When I first listened to the presentation I imagine a self-service scenario. But when I was talking to the OMS+ team about it they said no, this is actually for a customer scenario for when someone is asking multiple vendors for a bid or a quote. So the customer use case here is for a customer service representative to be able to create a quote for a variety of materials in a competitive and timely manner. Is that correct?
Juichia: Currently the customer representatives are receiving lists of material requests from customers that are usually in spread sheets. And the materials are described from the perspective of their customers and are in no way matching the SAP systems materials. Right now the sales representatives have to take the excel spreadsheet and make a manual mapping of the requests to SAP materials. And some of the unique challenges for example, there are scenarios where the customer request in no way matches the SAP material so when you score it from a similarity perspective using the system the similarity score between the matching pair is actually zero so that is a unique challenge for the system.
Cailin: Not knowing anything about data analysis or machine learning I’m assuming once we get pairs of customer descriptions and SAP materials paired that this will create information that the machine will use to learn and create similarities. Does it work like that. (okay, I cleaned that up a lot but that was the idea behind my Rose Tico “doing talking with data scientists is not my forte” muddle there.)
Juichia: Right. Going forward the more data we gather about the descriptions and the matches the more the machine can learn from the data and be able to be more accurate in the results.
Cailin: So it should get faster, because it sounds like with the data wrangling that is a very tedious process.
Juichia: Yeah, so right now we have already gone through the data processing pipeline for the material matching solution so we’ve taken the customer’s SAP material data and we’ve gone through data sourcing, wrangling, the analysis, feature engineering and statistical data analysis to do hypothesis tests and now we are into the phase where can take what we know from the data science work that we’ve done and implement the machine learning solution. The machine learning solution we are using right now implements a very common search engine method which is basically transforming the material descriptions into vectors of numbers and then compare the vectors of numbers to come up with the similarity scores.
Cailin: What is the next step?
Juichia: So we are going to try to engage user feedback into the pipeline. Once the user is presented with search results they will be able to have the option of providing feedback on whether the result is relevant or not. We will gather that data and be able to use that to improve the solution.
From an infrastructure perspective for machine learning we are looking at partnering with SAP to use SAP data intelligence and bring out data processing pipeline into the platform and connect directly to SAP HANA database so we can have an end-to-end solution for machine learning and be able to deploy these solutions directly using data intelligence and connect to OMS+.



[…] for more information about those capabilities. For now you can see what Juichai is working on here “AI in OMS+ project overview” and “Machine Learning and Artificial Intelligence Enhance the OMS+ […]